1. Overview
Whenever I tried to study PostgreSQL source code a little deeper, I always wanted to find some tools to help me understand better as I really don’t want to read the code line by line for a particular feature, but at the same time, I really wanted to figure it out quickly. Simply put, I was kind of “lazy” at that movement. Luckily, I found one very simple way to help me when I was studying the Geometric Types in PostgreSQL. This simple method helped me find out a bug exist since 1997. Thanks to Tom Lane who helpped fix it and committed it to Postgresql. The commit is “35d1eefb29d03d5a85f71038679f1f8a14358255” with below comments.
1 | Fix circle_in to accept "(x,y),r" as it's advertised to do. |
In this blog, I will use this story to explain how did I figure out this bug using a script in a very simple way.
2. Find a bug born in 1997
A few months ago, I was trying to see what was all the Geometric Types PostgreSQL can support by checking the official document. In the section 8.8.7. Circles, the different ways to insert a circle were described like below.
1 | Circles are represented by a center point and radius. Values of type circle are specified using any of the following syntaxes: |
I was so suprised that there are some many ways to draw a circle in PostgreSQL, and accidently I had a psql console connected to a server at that moment. So, I decided to try all the methods one by one. However, when I followed the 3rd way to insert a circle, I encountered an error, i.e. invalid input syntax for type circle. Here is the what did at that moment.
1 | CREATE TABLE tbl_circle(id serial PRIMARY KEY, a circle); |
The first thoughts came to my mind was that I must have typed something wrong. But after carefully checked each character, I couldn’t find any error. However, I conldn’t believe what I saw on the screen, therefore I called my colleague to help me do a quick check. The result was the same. Then I started to think if I can go a little further to find out the bug before reporting to the community, it might help some. But, the question was how to find the issue out within limited time (I did have a lot of work need to be done in the same day, in other words, “I was busy”. Well, “busy” is actually one of the main reasons I want to discuss about this simple method).
Obviously, I was not so familiar with the data type related circle in PostgreSQL source code, but I did know how to compile PostgreSQL from source code and how to use gdb to run a simple debug (keep in mind, these are all the prerequisite).
I started to compile the source code with gdb enabled like below../configure --enable-cassert --enable-debug CFLAGS="-ggdb -O0 -g3 -fno-omit-frame-pointer”
After the PostgerSQL server restarted, I used gdb to attach to the postgres running in background which connected to my psql console. I set up a breakpoint to the function transformExprRecurse (well, this is another prerequisite). I tried to repeat the circle insert query, and the gdb stopped at transformExprRecurse. Now, I was totally stuck. I didn’t know how to locate the bug, I had no idea what was behind the circle data type, and in which file it was implemented etc.. Then how could I move a litter further?
Well, I did have one thing in my mind that I need to quickly find out the difference between the working data type and the non-working data type. To achieve this, a simple way would be just type a next and then press enter. I started to do it. But after repeated 3 times, I gave it up. I realized that I didn’t know how many times I have to repeat the process and it was not possible for me to capture the difference. Then I started to question myself whether there was a way to automatically type next and then enter until the circle insert query was finished. Thanks to google, yes, I found this. I copied and pasted the script and added transformExprRecurse as the default breakpoint. The scpript was ended up like below,
1 | # file: step_mult.gdb |
I re-attach the postgres, ran the command source step_mult.gdb within gdb console, and then let the postgres continue to run in the background. I switched to another console and started to insert a circle using the 3rd way again. Postgres stopped at exec_simple_query, then I ran step_mult 10000. After a while, I saw the error message on my psql console again. I changed the log file gdb.log to gdb-2nd.log and repeated the steps, but this time I inserted a circle using the 2nd way. Now, I got two gdb log files which contain all the single step for the working and non-working circle data types.
I used a very nice Intelligent Comparison tools to compare these two gdb log files and I foud the difference like below. 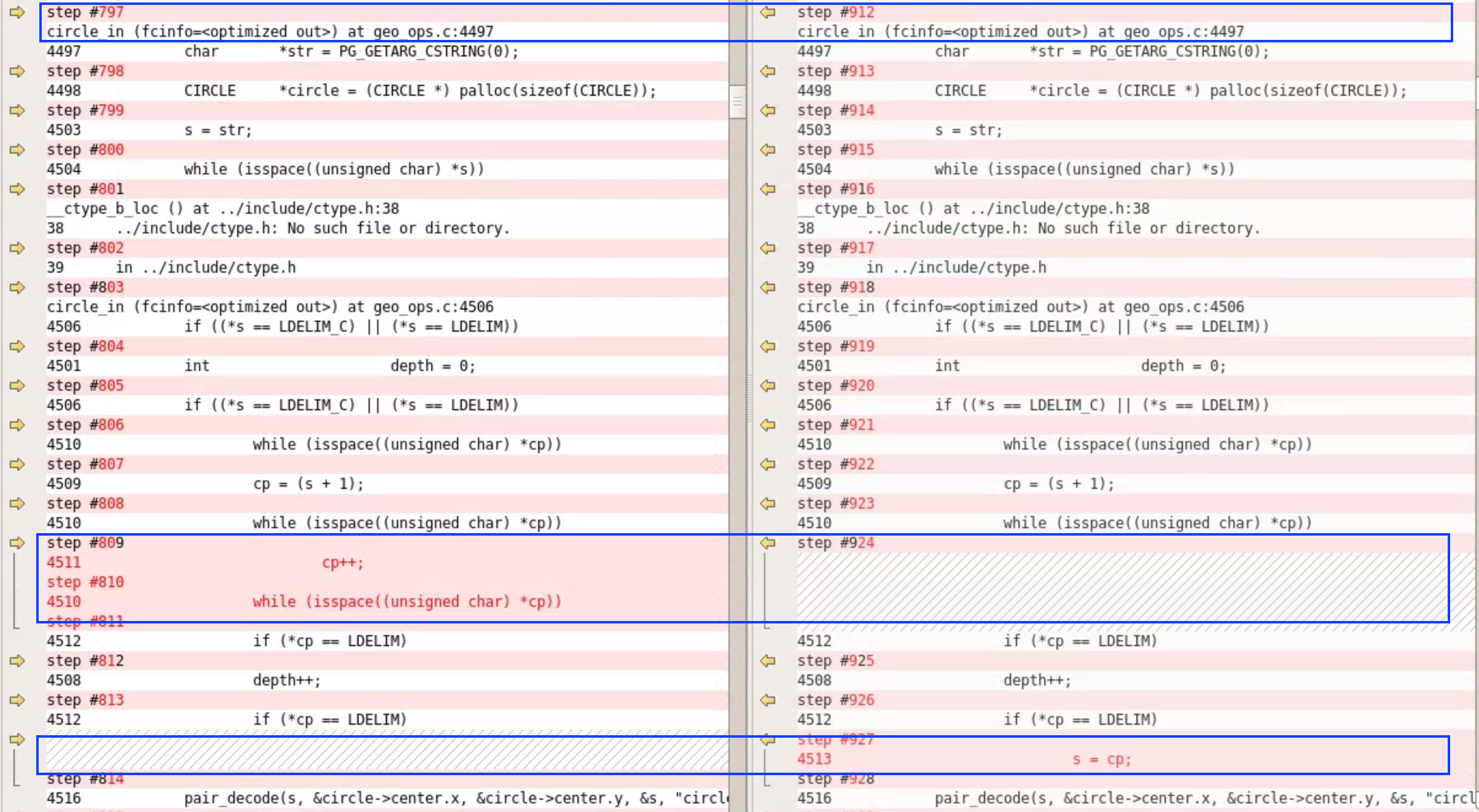 . The big difference I saw was showing in
. The big difference I saw was showing in circle_in function within src/backend/utils/adt/geo_ops.c.
Now, I figured out where the data type circle was implemented. To proof that it was the right place to fix this issue, I made a quick dirty fix. Then I performed a test and found the 3rd data type was kind of fixed.
At this point, I was more confident to report this issue to the community with my dirty patch to proof that PostgreSQL doesn’t work with the 3rd way to draw a circle. The entire process took me about an hour, but I think finding out a bug which has stayed in PostgreSQL about 23 years in an hour is not that bad.
3. Summary
PostgreSQL is one of the best open source RDBMS in the world, and there are many other open source projects like it. As a software engineer, you might encounter something like me in your daily work. If you find something fishy but don’t have enough time, then try the way I did. It may surprise you, who knows. From my opinion, this method may be suitable for below sisutations:
1) A feature is working in one use case but it doesn’t work in another very similar use case;
2) To find a function execution path in different conditions;
…