1. Overview
Nowadays, supporting distributed transactions is a typical requirement for many use cases, however, the global deadlock detection is one of the key challenging issues if you plan to use PostgreSQL to setup a distributed database solution. There are many discussions about global deadlock, but this blog will provide you a step-by-step procedure about how to create such a global deadlock and share some thoughts based on personal experience.
2. Deadlock
First of all, the basic concept of a deadlock is that Process A is trying to acquire Lock2 while it is holding Lock1 and Process B is trying to acquire Lock1 while it is holding Lock2 at the same moment. In this situation, Either Process A or Process B can’t not continue and they will wait for each other forever. Since PostgreSQL allows user transactions to request locks in any order, therefore, this kind of deadlock can happen. When this kind of deadlock is happening, there is no win-win solution, the only way to solve this locking issue is that one of the transactions has to abort and release the lock.
To address this deadlock issue, PostgreSQL has two key things built-in: 1) try to avoid the deadlock by having a lock waiting queue and sort the locks requests to avoid potential deadlock; 2) requires the transaction to abort if a deadlock detected; By having these two key designs, a deadlock happens within a single PostgreSQL server can be easily resolved. For more details information about the deadlock, you can refer to the official document at src/backend/storage/lmgr/README. In this blog, we call this kind of deadlock as local deadlock compared with the one (global deadlock) we are going to discuss more below.
The reason PostgreSQL can detect this local deadlock is because PostgreSQL knows all the locks information, and it can easily find a lock waiting cycle. In the source code, PostgreSQL defines a generic LOCKTAG data struct to let user transaction fill in different lock information. Here is how the LOCKTAG data struct is defined in PostgreSQL.
1 | typedef struct LOCKTAG |
In PostgreSQL, there are about 10 Micros defined to address different locks in different use cases, and you can find the details by searching below key info.
1 | #define SET_LOCKTAG_RELATION(locktag,dboid,reloid) |
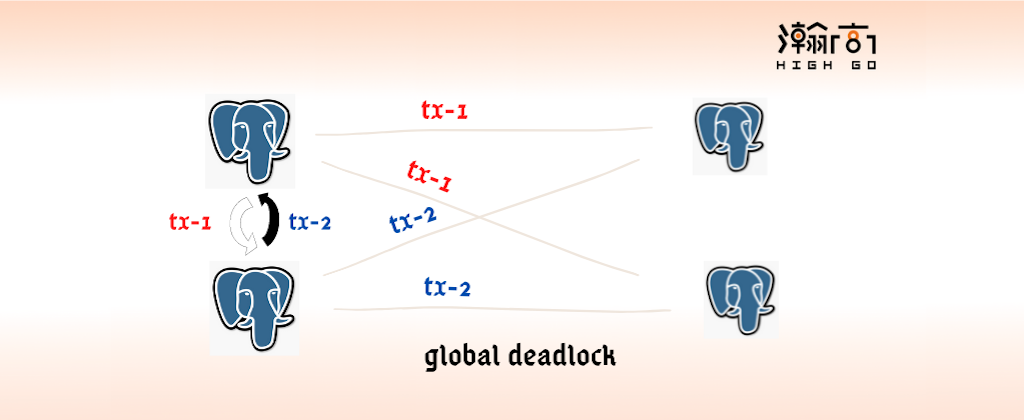
In a distributed PostgreSQL deployment environment (typically, one or more Coordinator Nodes plus multiple Data Nodes), a deadlock can happen globally, like the one described in Databases and Distributed Deadlocks: A FAQ. A deadlock triggered by Coordinator Node and caused multiple Data Nodes to wait for each other is called global deadlock or distributed deadlock. In this case, the original PostgreSQL can’t solve this problem as each Data Node doesn’t take this situation as a deadlock.
3. How to create a global deadlock
To better understand the global deadlock issue, we can create a global deadlock by following below steps. First, you need to install postgres_fdw extension to setup a simple distributed database cluster by running below commands.
3.1. Setup a simple distributed PostgreSQL database cluster
Assume you have installed PostgreSQL or built your own binaries, and then initialize four PostgreSQL servers like below,
1 | initdb -D /tmp/pgdata_cn1 -U $USER |
For each PostgreSQL database, edit the configuration files to set different port and cluster name. In this case, we have two Coordinator Nodes sitting on Port 50001 and 50002, and two Data Nodes listening on 60001 and 60002.
1 | vim /tmp/pgdata_dn1/postgresql.conf |
Start all PostgreSQL servers.
1 | pg_ctl -D /tmp/pgdata_cn1 -l /tmp/logfile_cn1 start |
3.2. Setup the Data Nodes
Run below commands to create table t on two Data Nodes,
1 | psql -d postgres -U $USER -p 60001 -c "create table t(a int, b text);" |
3.3. Setup the Coordinator Nodes
Coordinator Node setup is a little complicated. Here, we are using the postgres_fdw extension to create a simple distributed PostgreSQL database cluster, therefore, you need to follow below steps to setup the postgres_fdw extension, user mappings, and foreign servers and tables.
Setup the extension, foreign servers, user mappings, and tables on Coordinator Node 1.
1 | psql -d postgres -U $USER -p 50001 -c "create extension postgres_fdw;" |
Setup the extension, foreign servers, user mappings, and tables on Coordinator Node 2.
1 | psql -d postgres -U $USER -p 50002 -c "create extension postgres_fdw;" |
3.4. Create a global deadlock
Now, after you have setup this simple distributed PostgreSQL database cluster, you can run below commands in two different psql sessions/consoles to create a global deadlock.
First, insert one tuple on each Data Node.
1 | psql -d postgres -U $USER -p 50001 -c "insert into t values(1001, 'session-1');" |
Second, start two different psql consoles and run the tuple update based on below sequence indicated by (x).
1 | psql -d postgres -U $USER -p 50001 |
After, the update query (4) has been executed, you will end up like below waiting situation,
1 | postgres=# begin; |
If you grep postgres process using below command, and you will find two separate postgres from two different Data Node are in UPDATE waiting, and this will last forever.
1 | david:postgres$ ps -ef |grep postgres |grep waiting |
When the global deadlock is happening above, you can check the waiting process in details by gdb attaching to any of them. If you dig into the source code, you can find out that this global deadlock is actually related with SET_LOCKTAG_TRANSACTION.
1 | #define SET_LOCKTAG_TRANSACTION(locktag,xid) \ |
4. How to solve the problem
There are many discussions about global deadlock detection, like the one mentioned above Databases and Distributed Deadlocks: A FAQ, which has some recommendations like Predicate Locks and Wait-Die or Wound-Wait
And a very detailed one about how to detect a global deadlock at PostgreSQL and Deadlock Detection Spanning Multiple Databases, which recommends using a Global Wait-for-Graph to detect it.
Another approach is that instead of avoid the problems, or using wait-for-graph to find a cycle, we can also consider to have an independent program or even a simple database to help check if there is a global deadlock. Sometimes, the issue is hard to solve is because it is hard to get all the information. The reason we can easily see a deadlock caused by one or multiple Coordinator Nodes is because we take one step back and look at the situation as a whole picture.
5. Summary
In this blog, we discussed the basic global deadlock issue, setup a simple distributed database cluster using postgres_fdw and demonstrated a global deadlock. We also discussed different approaches to either avoid this global deadlock or solve it in different ways.