1. Overview
I was working on the PostgreSQL storage related features recently, and I found PostgreSQL has designed an amazing storage addressing mechanism, i.e. Buffer Tag. In this blog, I want to share with you my understanding about the Buffer Tag and some potential usage of it.
2. Buffer Tag
I was always curious to know how PostgreSQl can find out the tuple data blocks so quickly when the first time I started to use PostgreSQL in an IoT project, but I never got the chance to look it into details even though I knew PostgreSQL is an very well organized open-source project. Until I recently got a task which needs to solve some storage related issue in PostgreSQL. There is very detailed explanation about how Buffer Manger works in an online PostgreSQL books for developers The Internals of PostgreSQL, one of the best PostgreSQL books I would recommend to the beginner of PostgreSQL development to read.
Buffer Tag, in simple words, is just five numbers. Why it is five numbers? First, all the objects including the storage files are managed by Object Identifiers, i.e. OID. For example, when user creates a table, the table name is mapped to an OID; when user creates a database, the name is mapped to an OID; when the corresponding data need to be persistent on disk, the files is also named using OID. Secondly, when a table requires more pages to store more tuples, then each page for the same table is managed by the page number in sequence. For example, when PostgreSQL needs to estimate the table size before decide what kind of scan should be used to find out the tuple faster, it need to know the number of blocks information. Thirdly, it is easy to understand that data tuples are the major user data need to be stored, but in order to better manage these data tuples, PostgreSQL needs others information, such as visibility to manage the status of these data tuples, and free space to optimize files usage. So this ends up with five numbers, i.e. Tablespace, Database, Table, ForkNumber, BlockNumber.
Given these five numbers, PostgreSQL can always find out where the data tuples are stored, which file is used, and what size the table is etc.
3. How Buffer Tag is used
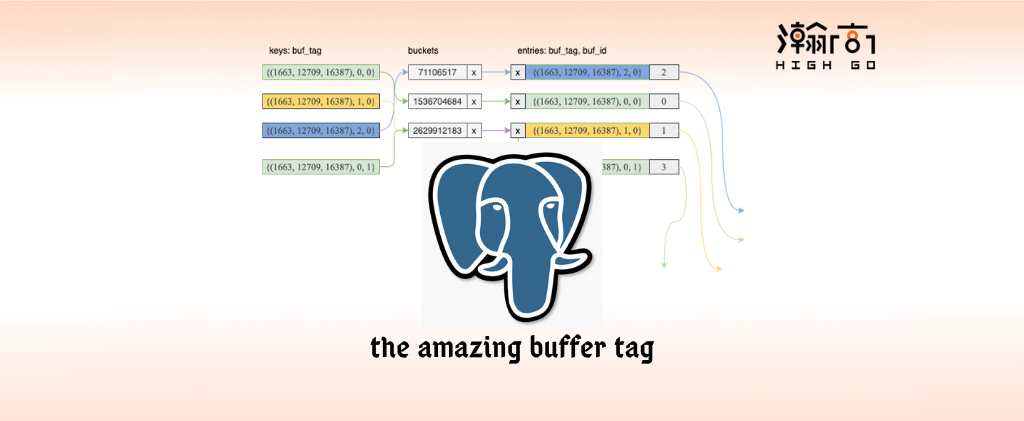
Now, we have the buffer tag, five numbers, but how it is used in PosggreSQL. One typical use case of buffer tag is to help buffer manager to manage the location of memory blocks in the buffer pool/array. In this case, a hash table was introduced to resolve the mapping between buffer tag and the location of memory block in buffer pool/array. Here is a picture to show relationship among buffer tag, hashtable, buffer descriptor, and buffer pool/array.
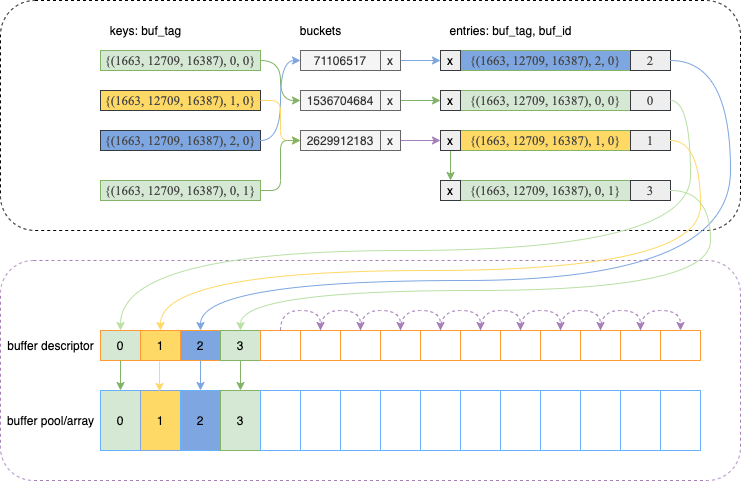
For example, the first green buffer tag {(1663, 13589, 16387), 0, 0} indicates a table space 1663, a database 12709, and a table 16387 with forkNumber 0 (main fork for tuples) which stored in a file at block 0. The buffer tag has a hash value 1536704684 which has been assigned to the memory block 0 managed by buffer manager at this moment. Since buffer descriptor is addressed using the same slot number as memory block in buffer pool/array, so they both share the same slot number 0, in this case.
With the above relationship, PostgreSQL can find out the memory block location or assign buffer slot to a new memory block for particular buffer tag.
The other typical use case of buffer tag is to help the storage manager to manage the corresponding files. In this case, the blockNumber is always to 0 since it doesn’t require multiple blocks to store more data. Here, you can create your use case of buffer tag. For example, use the buf_id as the number of blocks for each database relation instead of using it to indicate the memory block location. Moreover, you can also use the buffer tag plus the hashtable to manage multiple information such as having both buf_id for location of the memory block and adding a new attribute total to manage the number of blocks. You can achieve this by define a different buffer lookup entry. For example,
The original buffer lookup entry using buffer tag to lookup the location of memory block.
1 | /* entry for buffer lookup hashtable */ |
Below is an example of buffer lookup entry which can lookup both the location of memory block and the number of blocks used by this particular buffer tag.
1 | typedef struct |
4. Summary
In this blog, we discussed what is Buffer Tag, how it is used in PostgreSQL and some potential usage of Buffer Tag to address the mapping issues between tables to storage files as well as the lookup issues.
Reference: